Tune sources¶
Here we demonstrate included utilities for loading tune data.
from pyabc2.sources import load_example, norbeck, the_session
abcjs loaded
A few examples are included in the package, accessible with pyabc2.sources.load_example() (returns Tune) and pyabc2.sources.load_example_abc() (returns ABC string).
load_example("For the Love of Music")
Tune(title='For The Love Of Music', key=Gmaj, type='slip jig')
The tune source modules, demonstrated below, download tune data from the internet.
Norbeck¶
norbeck.load() gives us a list of Tunes for one of Norbeck’s tune type groups (e.g. ‘jigs’, ‘reels’, ‘slip jigs’).
tunes = norbeck.load("jigs")
print(len(tunes), "jigs loaded")
tunes[0]
downloading...
done
540 jigs loaded
Tune(title="Bride's Favourite, The", key=Gmaj, type='jig')
tunes[-1]
Tune(title='30-årsjiggen', key=Gmaj, type='jig')
The Session¶
the_session.load() gives us a list of Tunes loaded from a (frequently updated) archive of all of the tunes in The Session. This is a large dataset, so here we cap the processing.
tunes = the_session.load(n=500)
tunes[0]
downloading...
done
/home/docs/checkouts/readthedocs.org/user_builds/pyabc2/envs/v0.1.0/lib/python3.11/site-packages/pyabc2/sources/the_session.py:306: UserWarning: 20 out of 500 The Session tune(s) failed to load. Enable logging debug messages to see more info.
warnings.warn(msg)
Tune(title='$150 Boot, The', key=Gmaj, type='polka')
tunes[-1]
Tune(title='A Trip To The Cottage', key=Gmaj, type='jig')
tune = the_session.load_url("https://thesession.org/tunes/21799#setting43712")
tune
Tune(title='The Cherrytree', key=Gmaj, type='jig')
tune.print_measures()
01: G2 d c B G
02: G F G A F D
03: G2 d A G G
04: d e e f g g
05: G2 d c B G
06: G F G A F D
07: B c c g2 B
08: B c g a f d
09: G2 d c B G
10: G F G A F D
11: G2 d A G G
12: d e e f g g
13: G2 d c B G
14: G F G A F D
15: B c c e2 B
16: A G E G A F
17: E B e d B e
18: d e g d B e
19: f B g f B f
20: f g g g a a
21: g a f f g e
22: f g d e d B
23: B d e f g A
24: A B d A G F
25: E B e d B e
26: d e g d B e
27: f B g f B f
28: f g g g a a
29: b2 a a g e
30: f g e e d e
31: d f a e d e
32: d B A A G F
Data archive¶
The Session data archive (https://github.com/adactio/TheSession-data) has many datasets (pyabc2.sources.the_session.load_meta()),
which we can use in other ways besides parsing ABCs to Tunes.
For example, we can look for the most common ABC notes in the corpus.
%%time
df = the_session.load_meta("tunes", convert_dtypes=True)
df
CPU times: user 502 ms, sys: 236 ms, total: 737 ms
Wall time: 660 ms
| tune_id | setting_id | name | type | meter | mode | abc | date | username | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 18105 | 35234 | $150 Boot, The | polka | 2/4 | Gmajor | |:d>g fe|dB AG|E/F/G E/F/G|BA GF| d>g fe|dB A... | 2019-07-06 04:39:09 | NfldWhistler |
| 1 | 11931 | 11931 | 'G Iomain Nan Gamhna | slip jig | 9/8 | Gmajor | dBB B2 A BAG|dBB Bcd efg|dBB B2 A BAG|eAA dBG ... | 2012-05-17 07:49:26 | iliketurtles |
| 2 | 11931 | 48772 | 'G Iomain Nan Gamhna | slip jig | 9/8 | Amixolydian | |:dBB BBA BAG|dBB Bcd efg|dBB BBA BAG|e2A dBG ... | 2023-11-25 22:54:00 | birlibirdie |
| 3 | 15326 | 28560 | 'S Ann An Ìle | strathspey | 4/4 | Gmajor | |:G>A B>G c>A B>G|E<E A>G F<D D2|G>A B>G c>A B... | 2016-03-31 15:34:45 | danninagh |
| 4 | 15326 | 28582 | 'S Ann An Ìle | strathspey | 4/4 | Gmajor | uD2|:{F}v[G,2G2]uB>ud c>A B>G|{D}E2 uA>uG F<D ... | 2016-04-03 09:15:08 | DonaldK |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 51760 | 13875 | 24924 | Zuppa Inglese | jig | 6/8 | Gmajor | GAG GAB|cBc cde|d2B GAB|A2G E2D| GAG GAB|cBc ... | 2014-10-07 22:55:26 | Edward Nunn |
| 51761 | 6040 | 6040 | Ølland | waltz | 3/4 | Gmajor | AB|:c2 cd cB|A2 AB cd|e2 g2 f2|1 e4 AB:|2 e4 e... | 2006-07-28 15:19:26 | Kuddel |
| 51762 | 6040 | 17944 | Ølland | waltz | 3/4 | Ddorian | F2 FG FE|D2 DE FG|A2 c2- cB|A4-:| A2 FA FA|F2... | 2006-07-30 13:32:55 | ceolachan |
| 51763 | 6040 | 39239 | Ølland | waltz | 3/4 | Adorian | |:AB|c2 cd Bc|A3 B cd|e2 g2 f2|e4:| w:Var det... | 2020-10-11 19:23:21 | janglecrow |
| 51764 | 6040 | 39240 | Ølland | waltz | 3/4 | Aminor | AB|"Am"c2 cd "G"Bc|"Am"A3 B cd|"Em"e2 g2 "D"^f... | 2020-10-11 19:47:57 | Bazza |
51765 rows × 9 columns
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 51765 entries, 0 to 51764
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 tune_id 51765 non-null Int64
1 setting_id 51765 non-null Int64
2 name 51765 non-null string
3 type 51765 non-null category
4 meter 51765 non-null category
5 mode 51765 non-null category
6 abc 51765 non-null string
7 date 51765 non-null datetime64[ns]
8 username 51765 non-null string
dtypes: Int64(2), category(3), datetime64[ns](1), string(3)
memory usage: 2.6 MB
from pyabc2.note import _RE_NOTE as rx
rx
re.compile(r"(?P<acc>\^|\^\^|=|_|__)?(?P<note>[a-gA-G])(?P<oct>[,']*)(?P<num>[0-9]+)?(?P<slash>/+)?(?P<den>[0-9]+)?",
re.UNICODE)
This regular expression does also match letters in tune titles, say.
["".join(tup) for tup in rx.findall("the quick brown fox jumps over the lazy dog")]
['e', 'c', 'b', 'f', 'e', 'e', 'a', 'd', 'g']
But The Session stores the tune body separately (in the abc field) and encourages a bare-bones melody-focused approach, so we can expect to mostly be matching actual notes.
from pprint import pprint
cool = df.query("tune_id == 1 and setting_id == 1")
display(cool.T)
abc = cool.abc.iloc[0]
print(abc, "\n")
pprint([m.group() for m in rx.finditer(abc)], compact=True)
| 9760 | |
|---|---|
| tune_id | 1 |
| setting_id | 1 |
| name | Cooley's |
| type | reel |
| meter | 4/4 |
| mode | Edorian |
| abc | |:D2|EBBA B2 EB|B2 AB dBAG|FDAD BDAD|FDAD dAFD... |
| date | 2001-05-14 18:45:18 |
| username | Jeremy |
|:D2|EBBA B2 EB|B2 AB dBAG|FDAD BDAD|FDAD dAFD|
EBBA B2 EB|B2 AB defg|afec dBAF|DEFD E2:|
|:gf|eB B2 efge|eB B2 gedB|A2 FA DAFA|A2 FA defg|
eB B2 eBgB|eB B2 defg|afec dBAF|DEFD E2:|
['D2', 'E', 'B', 'B', 'A', 'B2', 'E', 'B', 'B2', 'A', 'B', 'd', 'B', 'A', 'G',
'F', 'D', 'A', 'D', 'B', 'D', 'A', 'D', 'F', 'D', 'A', 'D', 'd', 'A', 'F', 'D',
'E', 'B', 'B', 'A', 'B2', 'E', 'B', 'B2', 'A', 'B', 'd', 'e', 'f', 'g', 'a',
'f', 'e', 'c', 'd', 'B', 'A', 'F', 'D', 'E', 'F', 'D', 'E2', 'g', 'f', 'e',
'B', 'B2', 'e', 'f', 'g', 'e', 'e', 'B', 'B2', 'g', 'e', 'd', 'B', 'A2', 'F',
'A', 'D', 'A', 'F', 'A', 'A2', 'F', 'A', 'd', 'e', 'f', 'g', 'e', 'B', 'B2',
'e', 'B', 'g', 'B', 'e', 'B', 'B2', 'd', 'e', 'f', 'g', 'a', 'f', 'e', 'c',
'd', 'B', 'A', 'F', 'D', 'E', 'F', 'D', 'E2']
%%time
note_counts = (
df.abc
.str.findall(rx)
.explode()
.str.join("")
.value_counts()
)
note_counts
CPU times: user 3.53 s, sys: 490 ms, total: 4.02 s
Wall time: 4.01 s
A 697004
d 639421
B 632183
e 532800
c 432596
...
B2/4 1
e2// 1
^F,6 1
=F,2 1
=B,6 1
Name: abc, Length: 992, dtype: int64
note_counts[:20]
A 697004
d 639421
B 632183
e 532800
c 432596
G 426832
f 375519
F 302322
g 291114
E 254752
D 218108
a 195243
A2 92854
d2 90330
B2 76674
G2 72472
e2 57654
b 57430
c2 45618
C 42239
Name: abc, dtype: int64
👆 We can see that A (unit duration) is the leader, being a prominent pitch in many of the common keys.
5 in Dmaj
2 in Gmaj
1 in Ador, Amin, Amix, Amaj
Note
A implies A₄, the A above middle C, the A string on a violin, the lower register on the flute, etc.
Note
In general we don’t know the duration of A without context (L: header field, or based on M: if L: is not set).
However, in this case, we know that the The Session presets the unit duration to 1/8,
so A is an eighth note.
from textwrap import wrap
print("\n".join(wrap(" ".join(note_counts[note_counts == 1].index))))
b'2 _f4 b,,3 ^c,2 ^B,2 c'3/4 e'' =F, E5/2 f5/2 f'/2 B,1
D,1 =F,3 =F,,3 E,,3 _B,3/2 =G6 ^G' A/1 =B/4 G/1 B,// _a4
e,2 f/8 ^g/8 =c'4 _c' E75 =C, e'1 ^f2/3 ^c2/ A11 e2/4 A6//
^a// F//// F/// A4/3 ^A10 ^a8 _A,6 d6/ ^b/ D11 C6/ ^D/2
B,' f,3 D2/3 =c2/3 =A4 d1/3 a'/ ^G10 ^D6 ^D10 ^D8 A,12
^c'4 ^c'3 =A/4 g,/ d16 =c16 E24 _d/ E33 d'/4 ^A3/4 ^B3/4
f,8 =D6 e8/3 a8/3 c'1/2 c,3 C,12 A7/9 A16 ^^D4 ^^d4 ^^d3
^^D A,9 _d'3 e'3/2 ^f'2 G'4 F'3 =a3 A'4 D22 c7 a/3 B16
G16 A'/ a'4 e4/ f4/ =e// ^g/2 ^A// D/8 E/8 B/8 F5/ _a3/2
G,12 _e8 =c'3/2 ^e/2 ^A5 _E,2 G,,4 _g/ g,,2 B32 e23 ^E,2
B'/2 F,6 E,8 c3// D'/ C'/ =c1 _d6 B7/4 _c3 =e6 B11 _e'/
__d d14 _c'2 ^f/2 ^b4 D'' f9/ _G4 c9 _A4 =G8 F5/4 B4/
A2/4 B2/4 e2// ^F,6 =F,2 =B,6
👆 A variety of ABC note specs appear only once. Many of these have unusual durations or accidentals.
What if we ignore everything except the natural note name?
nat_cased_counts = (
note_counts
.reset_index(drop=False)
.rename(columns={"index": "note", "abc": "count"})
.assign(nat=lambda df: df.note.str.extract(r"([a-gA-G])"))
.groupby("nat")
.aggregate({"count": "sum"})["count"]
.sort_values(ascending=False)
)
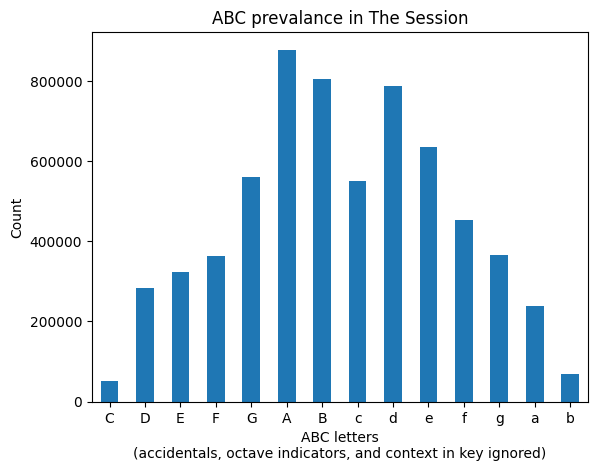
nat_cased_counts
nat
A 879349
B 804463
d 789330
e 634971
G 561676
c 551252
f 452672
g 366401
F 363493
E 324053
D 283423
a 239413
b 68184
C 51871
Name: count, dtype: int64
👆 A is still our leader, but otherwise things have shifted a bit.
Note C, which generally implies a pitch outside of the range of most whistles and flutes,
has the lowest count.
Although b is inside that range, many tunes don’t have one.
from pyabc2 import Note
(
nat_cased_counts
.to_frame()
.assign(value=lambda df: df.index.map(lambda x: Note.from_abc(x).value))
.sort_values("value")["count"]
.plot.bar(
xlabel="ABC letters\n(accidentals, octave indicators, and context in key ignored)",
rot=0,
ylabel="Count",
title="ABC prevalance in The Session",
)
);